- Published on
Real-time emotion recognizing
- Authors
- Name
- Tan Ngoc Pham
- @ngctnnnn

Introduce a deep learning approach to the problem of recognizing emotions in real time.
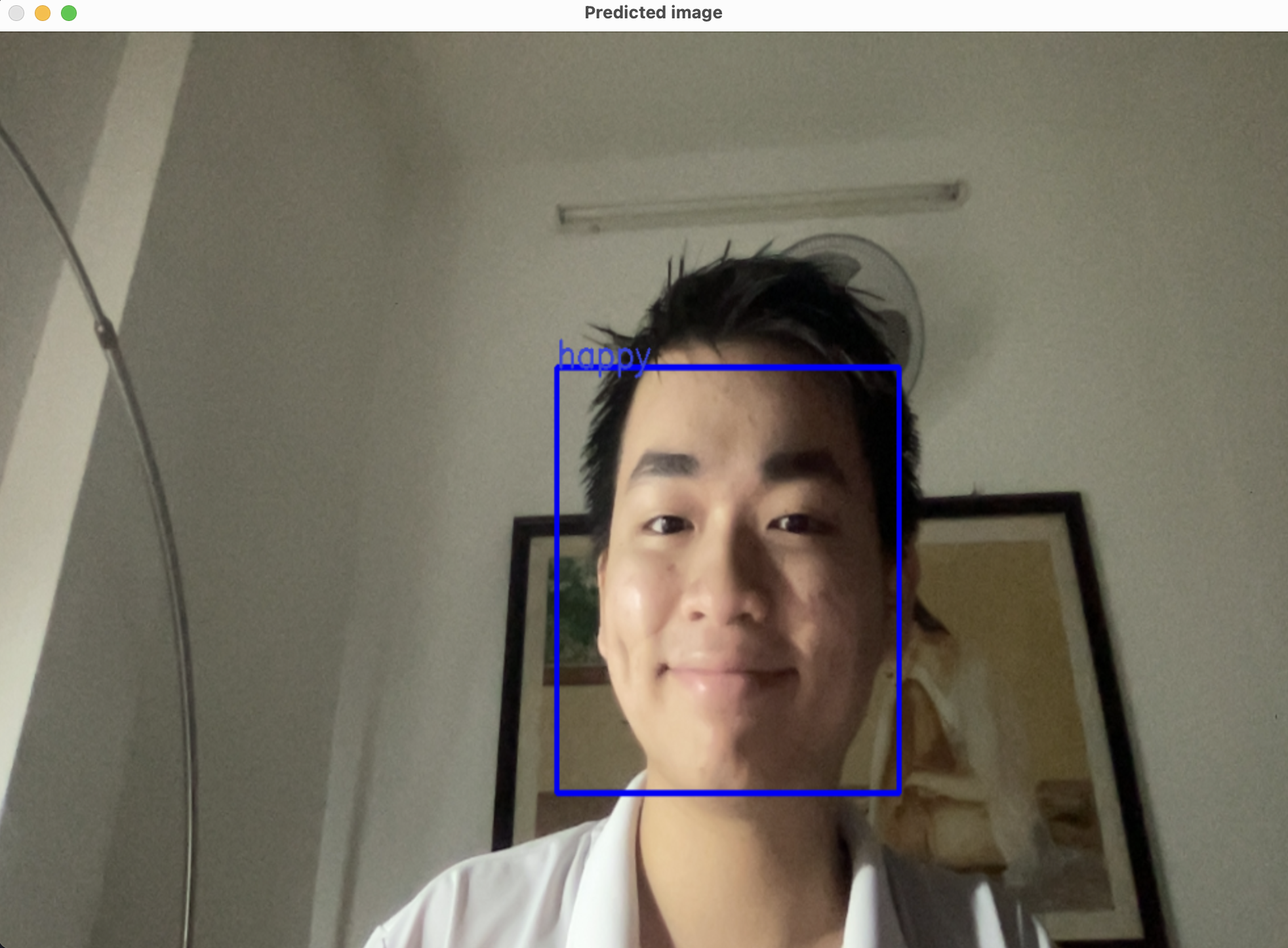
Table of contents
1. Introduction
There is a large number of neural networks nowadays to help us in almost every aspect of our life. In addition, we realize that different problems often require different types of networks. In this problem, I choose to use VGGFace network, or it is also called as Deep Face architecture.
VGGFace architecture was first introduced to solve the problem of recognizing humans' face (i think it is called as Deep Face at first due to that reason, in my opinion).
With that reason in mind, i think that VGGFace would perform well on other problems relevant to our faces as in the problem of emotion recognizing.
2. Dataset
The data using in this research is taken from Kaggle's FER-2013.
The data consists of 48x48 pixel grayscale images of faces. The faces have been automatically registered so that the face is more or less centred and occupies about the same amount of space in each image. The task is to categorize each face based on the emotion shown in the facial expression into one of seven categories (0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral). The training set consists of 28,709 examples and the public test set consists of 3,589 examples.
However, in order to get a sufficient data for my model training, as well as avoiding imbalance between data classes, i just take out 3 most important emotions which are happy, sad and neutral. I also get rid of the testing phase due to the limitation in data. The training set is divided into 2 smaller sets, which are training set (80%) and validation set (20%).
3. Proposed architecture
The originally proposed VGGFace architecture was shown as:

However, i did some minor change in the original architecture to give out a better performance to my own problem. In details, there is an extra layer after the second one, an extra dense layer in the fully connected one, the activation function utilized is ReLU and some dropout layer.
The detailed model is shown as:
''' First layer '''
model.add(Conv2D(filters=64, kernel_size=(5,5),
input_shape=(img_width, img_height, img_depth),
activation='relu', padding='same',
kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Conv2D(filters=64, kernel_size=(5,5),
activation='relu', padding='same',
kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.5))
''' Second layer '''
model.add(Conv2D(filters=128, kernel_size=(3,3),
activation='relu', padding='same',
kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Conv2D(filters=128, kernel_size=(3,3),
activation='relu', padding='same',
kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.5))
''' Extra layer '''
model.add(Conv2D(filters=256, kernel_size=(3,3),
activation='relu', padding='same',
kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Conv2D(filters=256, kernel_size=(3,3),
activation='relu', padding='same',
kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.5))
''' Fully connected layer '''
model.add(Flatten())
model.add(Dense(128,activation='relu',kernel_initializer='he_normal'))
model.add(BatchNormalization())
model.add(Dropout(0.6))
model.add(Dense(num_classes,activation='softmax'))
Additionally, i also create a callback with a demonstration as: the learning rate would reduce with a factor of 0.5 once 7 continuous epochs do not improve their performance; and an early stopping is set once the performance does not improve in 7 consecutive epochs.
early_stopping = EarlyStopping(
monitor='val_accuracy',
min_delta=0.00005,
patience=11,
verbose=1,
restore_best_weights=True,
)
lr_scheduler = ReduceLROnPlateau(
monitor='val_accuracy',
factor=0.5,
patience=7,
min_lr=1e-7,
verbose=1,
)
The training process is shown as:

We can notice our model just has to go through 43 epochs before coming to the early convergence.
Moreover, since this model is rather huge and we can not use the whole model to predict in such a limited time when we harness our model in real-time. I would save the weights from model into a json model, and in main program, we just have to load our weights in the json only.
fer_json = model.to_json()
with open("model/vgg-face-model.json", "w") as json_file:
json_file.write(fer_json)
model.save_weights("model/vgg-face.h5")
And voilà, here is our final result after training the model and you can see its performance exceeds our expectation.
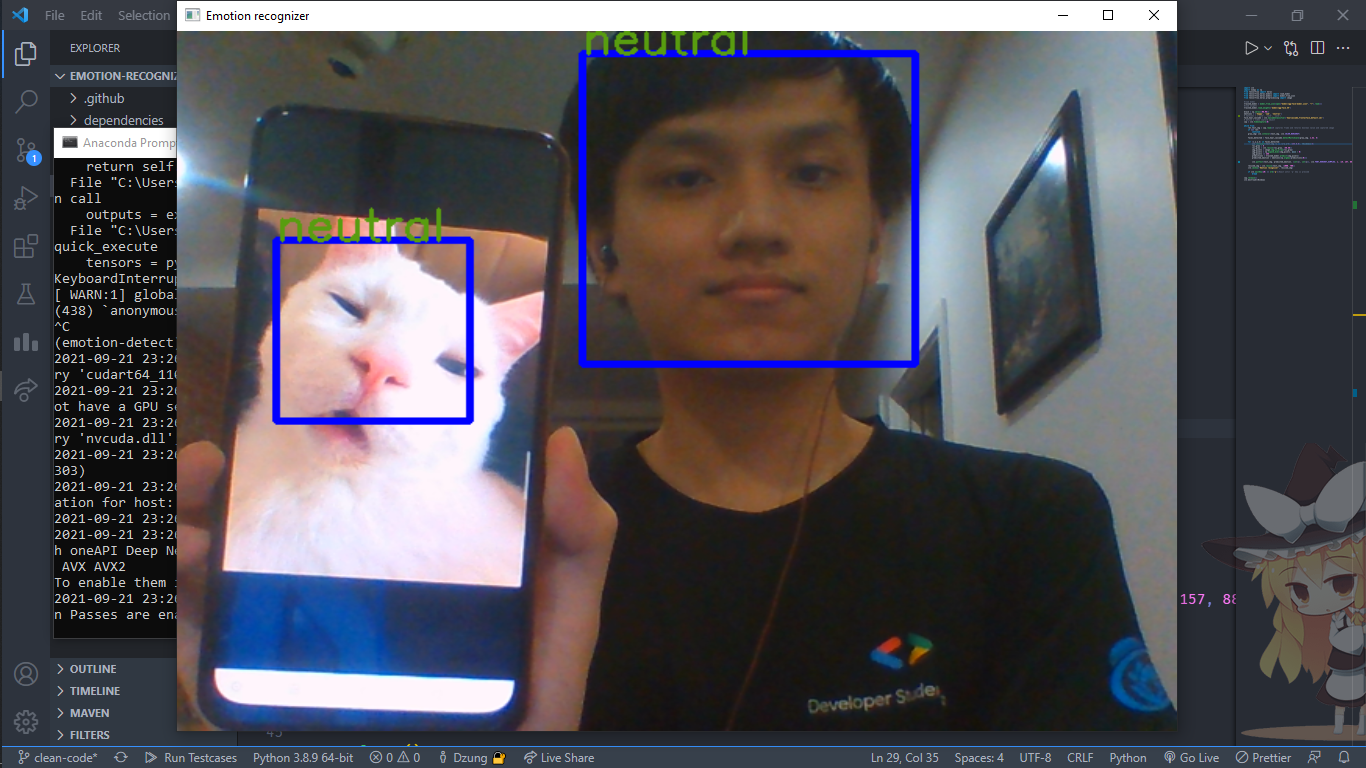
Detailed implementation here: ngctnnnn/RealTime-Emotion-Recognizer
4. References
[1] Qawaqneh et al. (2017). Deep convolutional neural network for age estimation based on VGG-face model. arXiv:1709.01664.
[2] I. J. Goodfellow et al. Challenges in representation learning: A report on three machine learning contests. Neural Networks, 64:59--63, 2015. Special Issue on "Deep Learning of Representations".